データは、自動運転機能を開発する際の最も貴重な財産です。dSPACEのデータドリブン開発担当プロダクトマネージャであるPatrik Moravekが、この財産をできる限り効率的に活用する方法について説明します。
Patrikさん、データドリブン開発とはどのようなものですか。
一般的に、データドリブン開発はソフトウェアの開発手法であり、人工知能(AI)ベースのアルゴリズム(具体的には、いわゆる機械学習用のAIのサブクラス)を含む手法を意味します。これは、新たな時代のソフトウェア開発形態だと言えます。この新しい開発手法は、AIベースの機能開発における新たな側面や課題に対応しているため、適切に活用すればより容易、迅速、かつ効率的な開発が可能になります。
自動車分野では、ADASおよび自動運転機能の開発を行う際に、車両の周囲の複雑な状況を分析する機械学習モデルを使用しています。これらのモデルの開発や設定には、実際の環境から得たサンプルのセンサデータが極めて大量に必要となるため、データの準備には、実に開発のほとんどの時間(とリソース)が費やされています。そのため、開発プロセスにおけるリソース配分が変更されると、それに応じて最適化すべき部分も変化します。つまり、コードの記述よりもデータの準備にコストがかかっているのであり、コストの最適化が必要なのはデータの準備段階ということです。データドリブン開発の手法では、こうした焦点の変化に適切に対処できます。
これは、ある意味でモデルベース開発(MBD)とも比較できます。MBDでは、ソフトウェア開発にモデルやシミュレーションを導入することで、特に制御領域における開発期間を大幅に短縮しました。また、開発段階を処理しやすい複数のステップに分割することで、複雑さの軽減やリソースの削減を実現し、プロジェクトの管理性を改善しました。これと同様に、データドリブン開発では、AIベースでの機能開発をすばやく効率的に行える特定のプロセスや方法、ツールを使用します。
データドリブン開発はどのような場合に適していますか。
最新の車両向けの新しい機能には、車線維持アシスタント(LKA)、渋滞時支援(TJA)、より高度な自動運転機能などがあり、これらは機械学習モデルを用いて実装された周辺認知能力に基づいて開発されています。この周辺認知能力を成熟させて実走環境でも使用できるようにするには、現実の環境から多数の事例をあらかじめ収集し、それらを開発や妥当性確認に活用する必要があります。この開発の際に、さまざまな特殊な事例を集めることができれば、(実走時の)車載ソフトウェアの信頼性はより高まります。データドリブン開発では、開発のある時点でプログラミングを中断したとしても、データ自体によって信頼性とパフォーマンスが向上していきます。
そのため、関連性のある(かつ特殊な)交通状況の事例を可能な限り多く収集し、着実なトレーニングおよび妥当性確認用のデータセットを構築することにより、実走時のソフトウェア障害を回避することが目標の1つとなります。つまり、自動運転向けのAIのパフォーマンスの決定打となるのがデータなのです。
小刀は小枝を切るには優れていますが、木を切り倒すのには向いていません。同様に、数メガバイトから数ギガバイトのデータを処理するツールで数テラバイトから数ペタバイトの膨大なデータを最適に処理できるわけではありません。

データドリブン開発における課題は何でしょうか。
主な課題となるのは、作業時のデータ量です。路上でのデータ収集や走行テストは、何十万または何百万キロメートルにも及び、収集するデータ量は数ペタバイトから数百ペタバイトにもなります。
そのような大量のデータを収集するには、コストをかけて大規模なストレージを構築することが必要ですが、それだけでなく、データ処理用の適切なプロセスやツールを準備することも必要になります。しかし、これらのツールは、データドリブン開発が登場する以前には存在していなかったものです。
切削工具が必要な場合を想像してみてください。小刀は小枝を切るには優れていますが、木を切り倒すのには向いていません。これと同様、数メガバイトから数ギガバイトのデータを処理するためのツールで数テラバイトから数ペタバイトの膨大なデータを最適に処理できるはずがありません。
また、路上で収集したデータがすべて同等に開発や妥当性確認に有用なわけでもありません。実際、収集されたデータの約90~95%は使いものにならないとも言われています。そのため、使用できるデータとできないデータの識別が重要になります。データドリブン開発では、開発や妥当性確認時に実際に価値のある走行データを収集、保存、および使用しつつ、価値のないデータを排除することが焦点の1つとなります。

dSPACEのソリューションとはどのようなものですか。
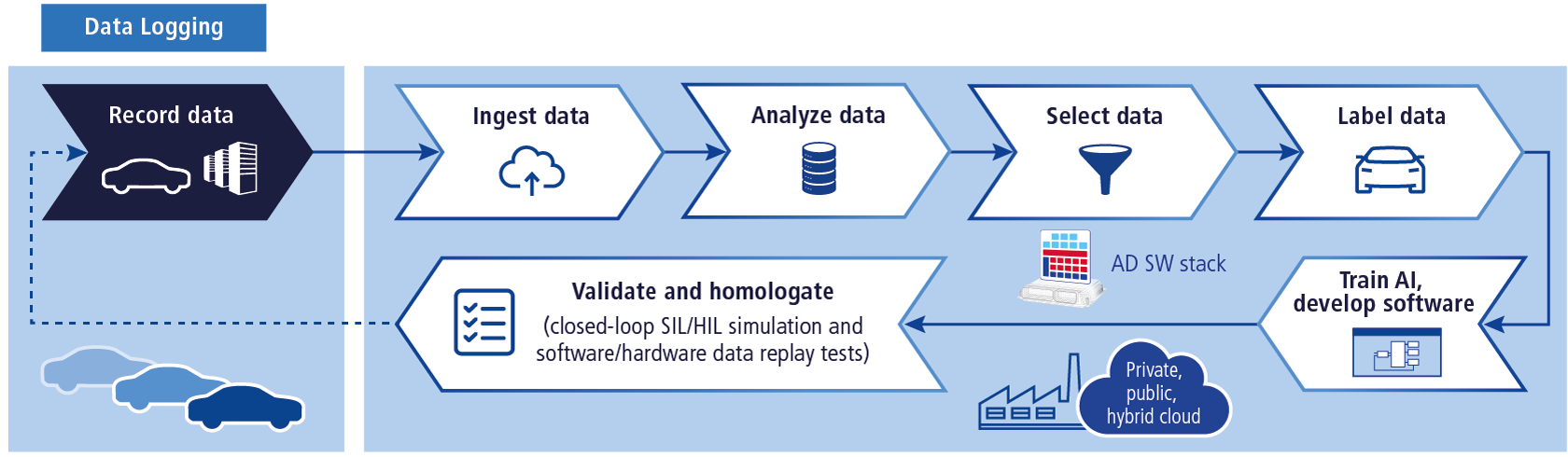
dSPACEは、シミュレーションおよび妥当性確認分野のパートナーとして、お客様がデータドリブン開発のさまざまなプロセスを改善できるようにするための各種ツールを開発し、それらの課題を早期の段階で特定してきました。当社の製品は、データ記録からデータリプレイ(または再処理)までのデータ経路全体に対応しており、クローズドループシミュレーションへの拡張もスムーズに行えるため、完全な仮想環境でADAS/AD機能の妥当性を確認することができます。
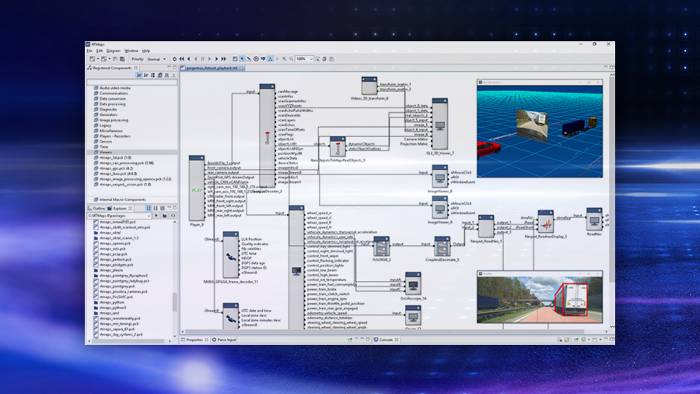
- データロギング をはじめとして、dSPACEではすべてのデータを記録し、オンボード解析を行い、記録データを最適化するための高機能なソリューションを提供しています。また、データロガーであるAUTERAやロギングソフトウェアであるRTMapsに対して、RTagでの手動のタグ付けやAIベースのフィルタリングを行えるように機能を拡張すれば、関連する状況だけを取得してデータ量の削減がかないます。
- 当社のUploadステーションを用いて高速な データインジェスト を行えば、不要な遅延の発生を防ぎながら開発者やテストエンジニアに確実にデータを届けることが可能です。
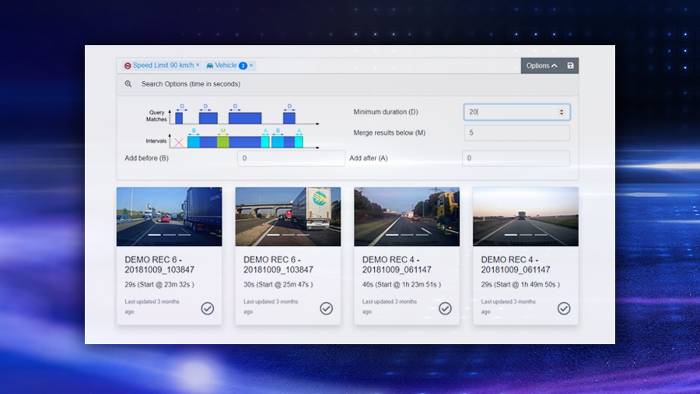
- (dSPACEのグループ会社である)Intempora社が開発した自動運転向けセンサデータ管理プラットフォームであるIVSでは、データのアクセス、ビジュアル表示、アノテーション、および選択のための各種機能が提供されているため、 収集したデータを効果的に活用 できます。
- 機能やシステムの妥当性確認は、計測された参考情報(グラウンドトゥルース)に対してのみ可能です。自動運転機能の開発では、グラウンドトゥルース情報を表すセンサからの受信データを アノテーション したものを参考情報とみなします。この分野に関しては、dSPACEのグループ会社であるunderstand.ai社が大規模なアノテーションの自動化に重点的に取り組んでいます。
- アノテーション処理された記録データの検証は、当社の データリプレイ システムを使用して行います。これについては、当社がアルゴリズムの検証用ツールやソリューションだけでなく、ハードウェアとソフトウェアで構築された完全なシステムを提供しています。データリプレイシステムは、お客様ごとの使用事例に応じて、RTMaps、VEOS、SCALEXIO、ESIユニットなどの当社の実績ある製品で構成することができます。
また、当社はお客様ごとの使用事例に適切に対応できるよう、記録データに基づいた妥当性確認(オープンループテスト)以外のデータの活用方法も提供しています。高品質なデータは、トレーニング用データセットの改善にも使用されます。さらに、記録データは妥当性確認作業をクローズドループ環境に移行するうえでも重要な役割を果たします。まず、IVSにプラグインを適用して交通状況を自動的に分析すると、関連する交通パラメータに対する理解を深めることができます。次に当社では、収集されたデータから合成シナリオを生成してクローズドループシミュレーションに適用する機能を提供することで、認証に至るまでの検証手法全体の計画と実行をスムーズに行えるようにしています。
dSPACEデータドリブン開発ソリューションの利点
- データの記録時にAUTERAのAIアルゴリズムを用いてデータを削減し、クラウドへのストレージコストの発生を防止。
- IVSにより、さまざまな地域から持ち込まれた実際のセンサデータを中央拠点にコピーすることなく、世界中に分散したデータセンターで分析およびプレビューして保存。
- IVSのジョブを高度に最適化されたランタイムエンジンに基づいて処理することで、計算時間を削減。
- 自動化されたAIベースのシナリオ検出機能やアノテーション時の各種オプションにより、データ分析の際の時間とコストを大幅に節約。
- Microsoft AzureやEquinixなどのハイブリッドアーキテクチャなどに合わせてデータリプレイソリューションのパフォーマンスを最適化。
どのような企業がパートナーとして協力していますか。
ADAS/AD機能の開発において、幅広いパートナーエコシステムは不可欠であり、お客様に開発作業を円滑に行っていただけるようにするための極めて重要な側面です。データドリブン開発をエンドトゥエンドで実現するためのストーリーやソリューション全体は、複雑なだけでなく複数の専門領域にまたがっているため、単一の企業では実現できません。当社では、お客様のあらゆる複雑な課題の解決をサポートするため、さまざまな分野に対応した多数のパートナーと緊密に連携しています。データロギングやデータリプレイについては、たとえば、Velodyne社、LeddarTech社、Robosense社、LeopardImaging社、Sensing World社などのセンサプロバイダ、OnSemi社、NXP社などのイメージチッププロバイダ、そしてNvidia社、Renesas社などのECUプロバイダと緊密な協力態勢を構築することで、システムをすばやく立ち上げられるようにしています。これにより、サプライヤ間の調整という非常に困難な作業を前もって軽減し、顧客満足度を大きく向上させることができます。また、コンピューティングインフラストラクチャについても、当社はAWS、DELL、IBM、Microsoft、SVAなどの企業と協力関係を築き、当社のシステムをさまざまな環境へ容易に展開できるようにしています。そのため、利用するリソースに応じて最大の効率性が実現可能です。多くの場合、異なる場所にあるソフトウェア、ハードウェア、およびデータ間の通信を効率的に行うには、高品質なネットワーク接続機能を提供するコロケーションセンターが必要になります。このため、当社が手を結んでいるのがEquinix社などです。
また、システムの統合や運用を含む車載統合サービスや管理サービスといったエンジニアリングタスク向けの当社のソリューションを柔軟に拡張できるようにするため、多数のエンジニアリング企業と緊密に協力しています。
つまり、当社は実に豊かで濃密なパートナーエコシステムを構築しています。そして、嬉しいことに、すべてのパートナーが当社と共にお客様のさまざまなニーズに非常に意欲的に対処してくれています。
お客様にとってのメリットは何でしょうか。
当社のツールやソリューションを活用すれば、お客様のデータドリブン開発プロセスが改善され、業務が効率化されて目標の迅速な達成が可能になるため、総コストも低下します。また、当社はお客様からのフィードバックを受けて、それを基にツールのさらなる向上を図ります。
当社の一貫性に優れた総合的なソリューションを活用すれば、お客様は統合にかかる時間とコストを大幅に節約できます。お客様は当社のソリューションで業務工程のほとんどを実現し、それを確実に補完するためにパートナーエコシステムを利用します。お客様が容易に統合作業を行い、リスクの低減も確保するには、できるだけ単一のソースやパートナーエコシステムを用いることが重要です。
当社では、常にモジュール性と拡張性を考慮しています。お客様には、プロジェクトの規模拡大に伴って、データドリブン開発ツールを徐々に拡大していくことを提案しています。小規模な環境から開始して、過去の投資の上に積み上げていくことができるからです。
当社のツールは再利用できます。お客様にとっての大きな利点は、複数のプロジェクトを通じてさまざまな用途に当社の製品を再利用できることです。HIL(Hardware-in-the-Loop)製品について考えてみましょう。dSPACE HILシステムをご使用のお客様は、データリプレイのハードウェア構成における本質的な要素であるHIL製品をデータリプレイテストステーションに合わせて調整することで、コストを大幅に節約できます。

将来の展望とdSPACEの今後の製品開発について教えてください。
当社は、お客様のデータドリブン開発プロセスの効率性を最大限に高めるという明確な目標を持っています。お客様が当社のツールを使用してコストと時間を節約しつつ安全な自動運転を実現することができれば、それはウィンウィンな状況だと言えます。当社は、これがパートナーシップだと捉えています。
当社は、データの中身やその価値を連続するステップで理解できるようなより良いデータインサイト手法を実現することにより、データパイプラインに沿ったデータの最適化や改善が可能になると考えています。データの記録段階で価値のないデータをすぐに判断できれば、直ちにコストの削減につながります。ただし、データの価値を理解するためのソリューションは無料で入手できるものではないため、データインサイト手法への投資か、データパイプラインに沿ったコスト削減のいずれかを選択しなければなりません。当社では、この課題に積極的に取り組んでいます。
AIは(記録データのシナリオ検出などの)データの理解において中心的な役割を果たしています。当社は既にAIアルゴリズムを搭載したツールを使用し、機能のさらなる強化に尽力中です。AIを活用すれば、データロギング、アノテーション、データ管理などの製品を強化することができます。当社はまた、dSPACE収集プラットフォーム(センサ搭載車両)に基づいた独自のデータ収集方法を用いることで、各種ツールの向上に役立つ使用事例を正確に特定できるようにしています。
インタビューにご協力いただきありがとうございました。
dSPACE MAGAZINE、2022年6月発行